Multiline Ultimate Assembler (an x64dbg plugin)
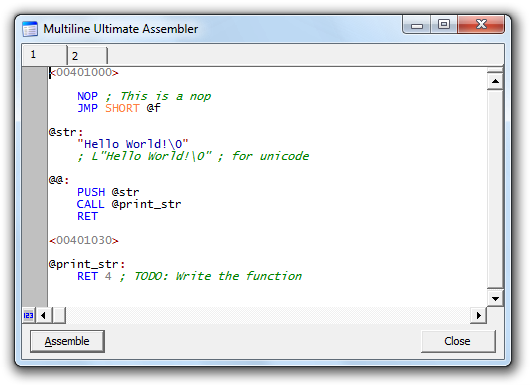
Multiline Ultimate Assembler is a multiline (and ultimate) assembler (and disassembler) plugin for x64dbg and OllyDbg. It’s a perfect tool for modifying and extending a compiled executable functionality, writing code caves, etc.
Source code:
https://github.com/m417z/Multiline-Ultimate-Assembler
![]() multiasm.rar (475.86 kB, changelog)
multiasm.rar (475.86 kB, changelog)
Posted in Releases, Software by Michael (Ramen Software) on September 13th, 2009.
Tags: multiline ultimate assembler, ollydbg, x64dbg
Tags: multiline ultimate assembler, ollydbg, x64dbg
its not support chinese in x64dbg.
i have changed font_name in x64dbg.ini,but its not working.
btw,i changed the resource to chinese and do something,still not wokring
What font did you try?
Here a user said that Tahoma worked for him: https://forum.tuts4you.com/topic/21128-multiline-ultimate-assembler/page/3/#comment-103871
Screenshot: https://i.imgur.com/67alKRO.png
Here a user suggested Microsoft YaHei UI: https://forum.tuts4you.com/topic/21128-multiline-ultimate-assembler/page/6/#comment-190530
Screenshot: https://i.imgur.com/LHn0BO6.png
Any chance to change this to asmjit in x64dbg? It seems to be using XEDParse which has issues.
I can’t get it to assemble “movss dword ptr ss:[rsp+0x18], xmm2”
Multiline Ultimate Assembler uses the debugger’s API for assembling instructions. For x64dbg, I believe that the last engine you used as a single command assembler is then used for the API. Try focusing on a command and pressing space, then select an engine and use it.
Yeah, that worked, thanks! 👍
Any idea how to add float ? or add it as hex directly?
@float 2.5
Or
BINARY dc cc cc 3c
Is there a syntax guide i can learn from?
You can use data instruction commands, for example
real4 2.5. See the relevant PR for details.You can use data instruction commands for that, too. For example, bytes:
Or a double word right away:
dd 12345678You can also use the plugin’s string syntax, for example:
"\x12\x34\x56\x78".Thank you for the tips!
Lovely software!
what about integers? When i do this
int 10
debugger shows
CD 10 00 00
where it is supposed to show:
0A 00 00 00
int 10is a software interrupt assembly command. Trydword 10. You can refer to the pull request I linked earlier.I do tried dword 10 but it produces the same result
10 00 00 00 and not integer 0A 00 00 00.
I looked through the pull request but did not find any relatable format the same way that is possible to say for floats ( real4 2.5 for example)
0A 00 00 00is much closer thanCD 10 00 00🙂 try using0x10instead of10for a hex value.hm.. that also produces 10 00 00 00
ok my bad i misread your comment, i think you misread mine or I did not explain correctly.
dword 10 produces 10 00 00 00
dword 0x10 produces 10 00 00 00
I am looking for 0A 00 00 00
i want input to be INT and output HEX
Sorry, it was a quick reply from my phone. I’m not sure that’s possible. Multiline Ultimate Assembler has some syntax that it understands, such as labels and address blocks, and the rest is forwarded to x64dbg. So it’s more of a question to x64dbg. They have a Discord channel, you might want to ask there.
Much appreciated :). Thank you for the prompt replies!
For xdbg plugin, it is better not to call IsDialogMessage, because it will modify the flow of the system message processing call, causing some unpredictable consequences. For example, for Chinese character set, raedit supports gbk encoding, but after the message processed by IsDialogMessage, the encoding received by WM_CHAR in the raedit message loop will be changed to unicode encoding. I spent a lot of time debugging to understand why it kept messing up after setting the font. Finally I commented out the following two lines and found that everything worked.
//if(IsDialogMessage(hWnd, lpMsg))
// return TRUE.
I’m not using Chinese, so I never experienced this problem. `IsDialogMessage` is used for other things, too, such as navigation with the tab key. There must be a more correct fix for that. If you find a better fix, let me know and I’ll consider including it in the plugin.